Patterns for AI Reliability
/ 7 min read
Table of Contents
The core challenge in building AI-native software is bridging the gap between the probabilistic nature of AI and the deterministic reliability users expect from traditional software.
A service like Amazon S3 is engineered for 99.999999999% (“eleven nines”) data durability; basically a guarantee that your data won’t be lost or corrupted. It’s so good that the average engineer never even thinks about what happens in that 0.000000001% of the time.
In contrast, AI calls can often have a success rate below 90%. We aren’t even talking about “one nine”!
Successfully deploying autonomous, multi-step AI workflows means navigating a fundamental trade-off between cost, latency, and correctness.
I have spent the last decade building large scale, reliable AI systems. The following patterns have consistently worked across a wide variety of industries and problems. And now they can work for you too.
1. Decompose complex tasks
The most effective architectural principle for improving reliability is to “divide and conquer”. Instead of giving a Large Language Model (LLM) a single, complex prompt with many instructions, break the task down into a series of smaller, more focused sub-tasks.
It is far easier to achieve high reliability on a small, well-defined task than on a large one. Models can only follow so many instructions at once.
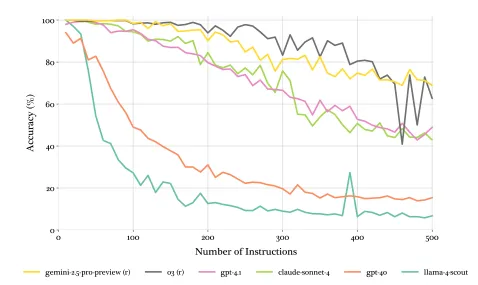
This approach, known as task decomposition, has several advantages:
- Reduces Cognitive Load: Large inputs can degrade an AI’s accuracy or cause it to get “lost” in the complexity of the request. Smaller, simpler prompts increase the probability of a correct response
- Enables Course Correction: A modular pipeline allows you to validate the output of each step before it’s passed to the next. This transforms an opaque process into an observable workflow where failures can be isolated and addressed at their source
- Improves Maintainability: These smaller, modular components are easier to debug, test, and eventually replace with cheaper, faster, or more reliable fine-tuned models over time
2. Elicit reasoning with chain-of-thought
Chain-of-Thought (CoT) is a prompt engineering technique that encourages an LLM to generate a series of intermediate reasoning steps before arriving at a final answer. Effectively, you’re asking it to “think out loud”. Originally developed to improve performance on complex arithmetic and commonsense problems, CoT has become a critical tool for reliability.
The main benefit is interpretability. The reasoning trace provides a transparent window into the model’s process, allowing developers to debug why a failure occurred. Instead of a black box, you get an auditable trail that often reveals the exact point where the model’s logic went wrong.
Interestingly, research shows that the effectiveness of CoT relies more on teaching the model a pattern of step-by-step thinking than on the factual accuracy of the examples provided. Prompts with invalid reasoning steps can still achieve 80-90% of the performance of those with perfect examples, as long as the steps are relevant and correctly ordered.
However, you must be careful. Research has shown that reasoning only works “in domain” (ie data the model was trained on). Outside of this, reasoning and chain of thought can actually degrade performance.
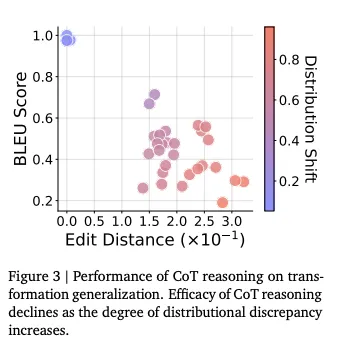
3. Enforce structured outputs with validation
For AI workflows to integrate reliably with other software, their outputs must be machine-readable. Simply asking an LLM to “respond in JSON” is not enough; the model can still produce malformed JSON or deviate from the desired schema.
A more robust solution involves two layers:
- Forced Structuring: Use model-native features like OpenAI’s “tool-calling” or a dedicated “JSON mode.” These capabilities constrain the model to generate output that strictly conforms to a provided JSON Schema, guaranteeing a syntactically correct structure
- Schema Validation: Use a data validation library to act as a guardrail, ensuring the output’s content and types are correct before they enter your application. This prevents malformed data from causing errors in downstream processes
For Python, Pydantic is the standard. It uses Python type hints to define a data contract. When LLM output is parsed, Pydantic automatically validates the data, coerces it into the correct types, and raises a detailed error if any rules are violated. For Typescript, Zod is the standard.
Several libraries help you implement this pattern: instructor, mirascope, mastra.
4. Generate multiple responses and select the best
Because LLM outputs are probabilistic, running the same prompt multiple times can yield different results. This can be leveraged to improve reliability. Instead of a single generation, you can create ‘K’ independent responses in parallel and then use a subsequent process to select the best one.
For example, let’s say the LLM is primarily outputting “yes” vs “no” responses and is correct 80% of the time. If we run the same prompt K=10 times and take the majority vote, we would expect reliability to be ~96% (with the increased cost of 10x calls). But not all problems can be solved with majority voting and require a selection method to pick the best response.
A common selection method is using another, more powerful model as an “LLM as a Judge”. This approach is often viable because judging or evaluating a response is a simpler and more reliable task for an AI than generating one from scratch. The judge can perform a pairwise comparison (“Is response A or B better?”) or score a single response against a rubric with criteria like helpfulness, correctness, or relevance.
While it may seem like adding another LLM call will just decrease reliability, in many problems the difficulty of generating a good response is much higher than the difficulty of judging a good response. And judging the relative quality of multiple responses is even easier, as shown by techniques like Ruler by OpenPipe
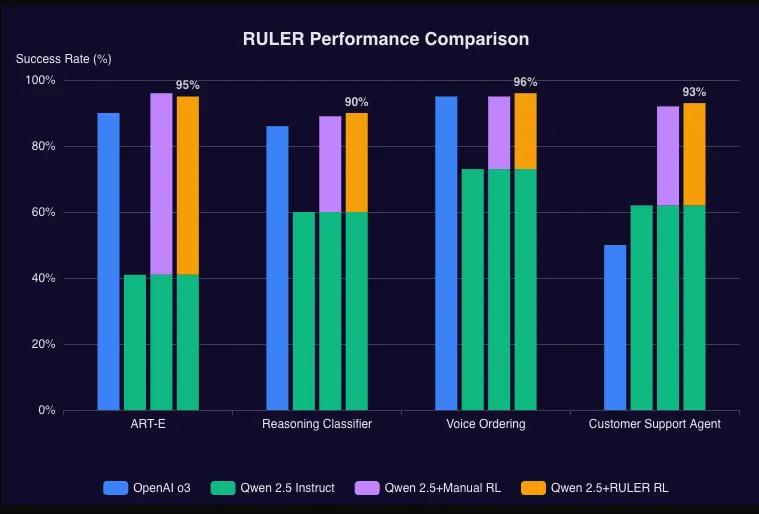
Other consensus techniques include:
- Self-Consistency: For tasks with discrete answers (like math problems), this method generates multiple reasoning paths and takes a majority vote on the final answer.
- Generative Self-Aggregation (GSA): For open-ended tasks, this technique feeds several diverse responses back to the LLM and asks it to synthesize a single, improved final answer that combines the strengths of the initial samples.
5. Add a layer of semantic validation
While syntactic validation checks if an output’s structure is correct, semantic validation checks if its meaning is correct. This is a more advanced form of validation where another LLM evaluates an output against complex, subjective, or contextual criteria that are difficult to express in code.
For example, a semantic validator could be instructed to check that a generated summary is “factually accurate and faithful to the source text” or that user-facing content is “family-friendly and adheres to community guidelines”. This is powerful but adds another stochastic AI call to your workflow, which increases cost, latency, and introduces its own reliability challenge. This technique is best applied strategically at critical points, such as right before an output is shown to a user.
You must remember that this is yet another AI component though, and you should observe, diagnose, and improve it like any other AI component.
6. Implement intelligent retries on failure
When a validation check fails or an API call errors out, the system shouldn’t just quit. A production-grade workflow must include a retry mechanism with escalating strategies to guide the model toward a correct output.
For transient API issues like rate limit errors, the standard solution is retrying with exponential backoff. This involves waiting for a short period after a failure, then re-issuing the request. If it fails again, the waiting period is increased exponentially for each subsequent attempt, often with a small amount of random “jitter” to prevent multiple clients from retrying in unison.
For validation failures, more sophisticated strategies can be used. And these often are better or cheaper than using a more powerful model
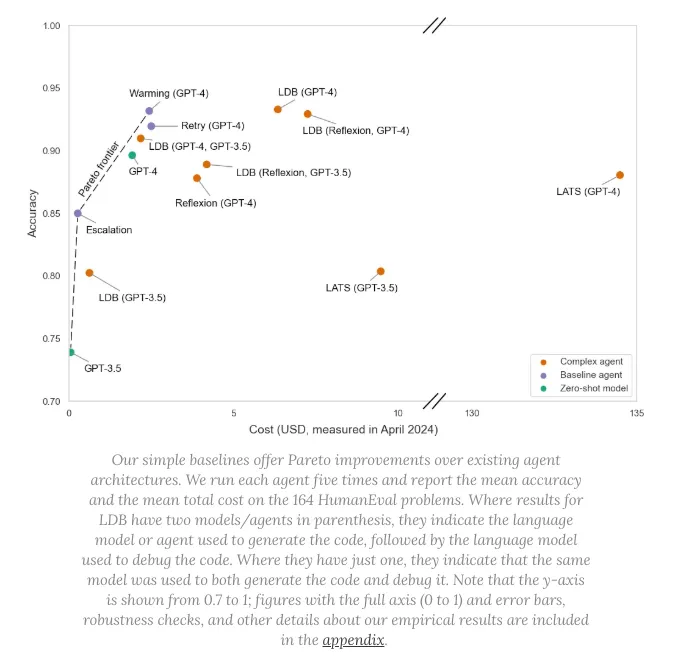
- Error Insertion: Feed the previous incorrect output and the resulting validation error message back into the prompt. This gives the model context on its mistake so it can self-correct.
- Model Escalation: Retry a failed call from a cheaper, faster model (like Haiku or Gemini Flash) with a more powerful and expensive one (like Opus or GPT-4o).
- Warming: Increase the temperature to encourage more “creative” responses
By layering these proactive and reactive strategies, you can build AI systems that are predictable, debuggable, and trustworthy enough for production.
Want to learn how to apply these patterns to your own projects? Book a free call with me.