Bringing Data Science Back to AI Engineering
/ 5 min read
Table of Contents
When I started in AI over a decade ago, machine learning wasn’t mainstream. Companies were investing (Google, Facebook, LinkedIn) but the focus was different. Teams struggled to get models that worked and kept working. The chasm between a data scientist’s notebook that “kind of worked” and production-grade infrastructure was enormous.
The problem then was clear: not enough people could build AI. Every company I worked at faced the same constraint. And that struck me as odd, because when I started ML projects, I consistently found low-hanging fruit. If you began with reasonable defaults and actually looked at your data, you didn’t need deep expertise. You just needed some basics.
So I spent years democratizing access: co-creating LinkedIn’s AI Academy, building infrastructure to support AI, and teaching engineers to do AI work. The barrier to experimentation dropped. Engineers with basic knowledge and infrastructure with decent guardrails could get pretty far. Eventually you might need specialized expertise, but first you needed to try things and see if they worked.
Fast forward to today: everyone is an AI engineer. The accessibility is remarkable. But the fundamentals haven’t changed. The same processes from the ML era apply to the generative AI era. The difference is that we have an influx of builders without (1) basic data science knowledge or (2) infrastructure with the right guardrails.
This is why we’re still having the same conversations:
- Benchmarks without confidence intervals
- LLM-as-a-judge without accounting for bias
- RAG systems with no systematic evaluation
- Thrashing through whack-a-mole improvements that never quite land
The space lacks data science fundamentals.
The MLOps era built guardrails for a reason
In 2015, D. Sculley and colleagues at Google published “Hidden Technical Debt in Machine Learning Systems”, a paper that should be required reading for every AI engineer today. The most striking diagram shows a production ML system: a tiny box labeled “ML Code” surrounded by massive infrastructure for data collection, feature extraction, configuration, monitoring, serving, and resource management.
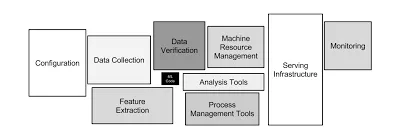
The “intelligence” part looks trivial compared to everything else. And that everything else exists because production ML systems require rigorous engineering to avoid what the paper calls “technical debt”: boundary erosion, entanglement, hidden feedback loops, undeclared consumers, configuration sprawl… The same set of problems you can find yourself in when building AI systems today!
The MLOps movement emerged to address this complexity. Feature stores standardized feature engineering. Model registries tracked versions and lineage. Observability tooling caught drift and regressions.
Generative AI has the same problems, but we’re acting like they’re new. We’re rebuilding the same guardrails from scratch, slowly, while pretending prompt engineering is a substitute for evaluation rigor.
The pattern I keep seeing
An engineer without AI experience eagerly jumps in. They wire up an LLM, write some prompts, get it working in a demo. Then they find it isn’t quite good enough. So they start thrashing:
- Try a different model
- Rewrite the prompt seventeen times
- Add few-shot examples
- Mess with temperature
- Throw RAG at it
- Try chain-of-thought
- Add a second LLM to check the first LLM’s output
- Go back and rewrite the prompt again
They never establish a baseline. They never measure systematically. They don’t know if the last change made things better or worse because they’re eyeballing outputs. They’re guessing.
This isn’t a new problem. We solved this in the ML era with train/validation/test splits, cross-validation, ablation studies, confidence intervals, statistical significance testing. We built infrastructure to enforce these practices because we learned that without them, you could waste months chasing ghosts.
Bad Example: You change your RAG retrieval from top-5 to top-10 chunks. You spot-check a few queries. They “look better.” You ship it. Two weeks later, user complaints roll in, and when you dig into it, recall improved 3% but precision dropped 18%. You roll back.
Good Example: You change retrieval from top-5 to top-10. You run both versions against a held-out eval set of 500 queries with ground truth. Top-10 improves recall by 3% (±1.2%) but drops precision by 18% (±2.1%), and p90 latency increases 400ms. You decide the trade-off isn’t worth it and keep top-5. Total time: 20 minutes. Zero user impact.
The difference here is systematic evaluation.
What data science fundamentals actually mean
I’m not even talking about advanced statistics or exotic algorithms here. I’m talking about:
1. Establish a baseline Before you try to improve anything, measure what “success” looks like and capture your starting point. If you can’t articulate what good looks like, you’re not ready to build.
2. Change one variable at a time Every time you change multiple things simultaneously, you lose the ability to attribute causation. This is experiment design 101.
3. Measure with held-out data The queries you used to tune your prompt are now contaminated. You need a separate eval set you haven’t touched. If you don’t have one, you might be fooling yourself!
4. Quantify uncertainty “Accuracy went from 85% to 87%” is meaningless without knowing if that’s noise. Confidence intervals, error bars, significance tests: pick one and use it.
5. Automate evaluation If you’re manually reviewing outputs every time you make a change, you will cut corners. Invest in automated eval infrastructure early, even if it’s imperfect.
These practices aren’t meant to gatekeep. They are intended to help you avoid wasting your time. So you can spend more of your time on the things that actually matter.
The pendulum swings back
The previous phase of my career was about bringing more engineering into data science: making ML teams ship faster, more reliably, at scale. I taught engineers to be dangerous with models so we could unlock capacity.
The next phase is the inverse: bringing data science (back) into AI engineering.
Not to gatekeep. Not to slow people down. But to equip the next generation of AI engineers with the fundamentals they need to actually be dangerous. To ship confidently, to debug systematically, and to know when something actually works instead of guessing.
Because right now, we’re watching people speedrun the same mistakes we made a decade ago. And the MLOps infrastructure we built to prevent those mistakes? It’s still relevant. The principles still apply. We just need to adapt them to LLMs, to RAG, to agentic workflows.