Table of Contents
Picture this: A data scientist spends hours configuring YAML files, debugging pipeline errors, and switching between five different tool UIs just to test a simple feature idea. Meanwhile, an analyst in Excel has already cleaned their data, built a model, and presented insights to stakeholders. Something’s wrong with this picture. The analyst using Excel is doing just fine.
The hidden complexity in data science work
Data science is inherently complex, requiring collaboration across diverse roles: data scientists producing insights, engineers making data available, and domain experts translating real-world problems into data. But our current tools often add unnecessary complexity to this already challenging work.
Consider these real-world scenarios:
The modern data science experience: Chloe’s story
Chloe, a data scientist, is improving a book recommendation system. Her “modern” stack includes a feature store, model store, and evaluation store.
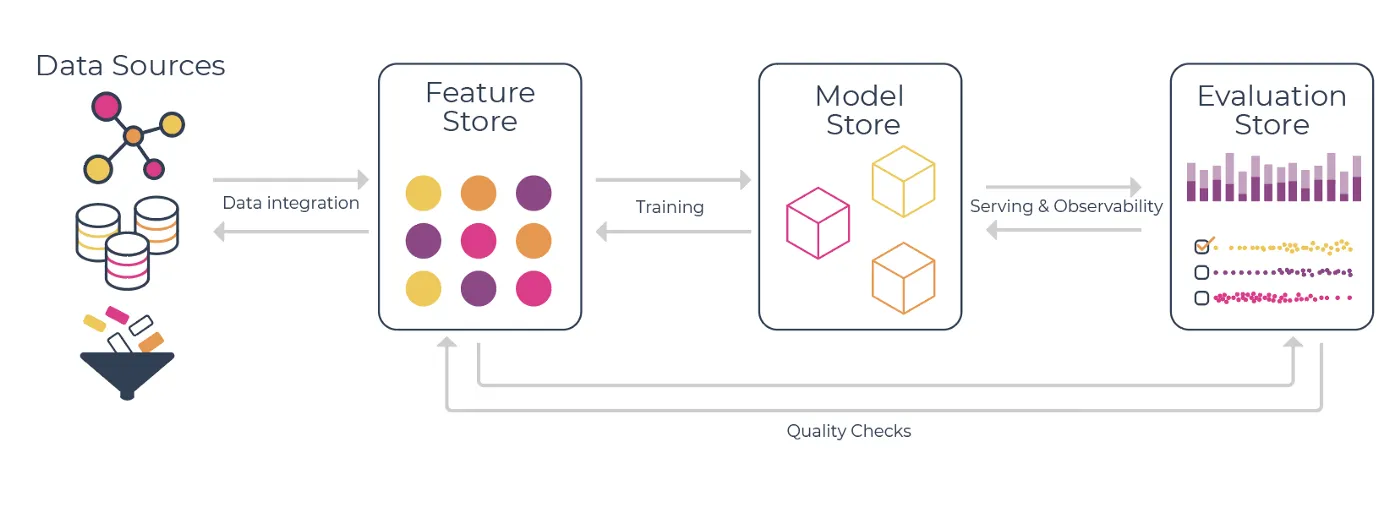 Credit: Aparna Dinakar
Credit: Aparna Dinakar
Here’s her typical workflow:
- She starts by checking model metrics across two separate UIs
- To understand poor recommendations, she digs through the evaluation store
- When she spots a potential improvement, she prototypes in a notebook
- To productionize her feature, she must:
- Rewrite notebook code into a specific format
- Create YAML configurations
- Debug deployment issues
- Wait 20+ minutes for feature computation
- After all this infrastructure work, she discovers a bug in her feature
- She starts the entire process over again
The analytics experience: Larry’s story
Larry, an analyst investigating customer churn, has a radically different experience with Excel:
- He loads customer order data directly into Excel
- When he spots data issues, he fixes them immediately using built-in functions
- He visualizes patterns by selecting columns and creating charts
- When he needs marketing data, he imports it and joins it right there
- He iterates on his analysis in real-time, cleaning and modeling as he goes
- He produces insights ready for stakeholder review
Both are solving data problems. Both need to clean data, analyze patterns, and build models. Yet their experiences couldn’t be more different. Chloe spends most of her time wrestling with infrastructure, while Larry spends his time solving the actual problem.
Why data science is a “wicked problem”
Data science challenges share key characteristics with what design theorists call “wicked problems”:
- The solution shapes the problem: How we model data influences what solutions we can discover
- Multiple stakeholder perspectives: Each role brings different priorities and constraints
- Evolving constraints: Requirements and resources change as understanding deepens
- Never truly finished: Solutions require continuous refinement and adaptation
This isn’t just academic theory – it explains why our current tooling often falls short. We’ve optimized for production stability while sacrificing the iterative nature of data science work.
Consider this example of modern ML infrastructure:
 Is this really how data scientists want to work?
Is this really how data scientists want to work?
What makes Excel work (despite its flaws)
Excel has serious limitations:
- Limited scale
- Poor version control
- Lack of audit trails
- Potential stability issues
Yet people keep using it. As Gavin Mendel Gleason aptly notes:
“People refuse to stop using Excel because it empowers them and they simply don’t want to be disempowered.”
Excel succeeds because it provides two critical capabilities:
- Iterability: Users can rapidly experiment, seeing results immediately
- Accessibility: Anyone can view and work with the data at their skill level
Excel succeeds because it focuses on the essential problem (understanding data) rather than accidental complexity (infrastructure concerns).
Building better data science tools
To create better tools for data science, we need to learn from Excel’s success while addressing its limitations. Future tools should:
1. Embrace accessibility through layered APIs
- Provide simple interfaces for basic operations
- Enable progressive complexity for advanced users
- Support different user roles and skill levels
- Example: FastAI’s layered API approach, allowing both high-level and low-level control
2. Enable rapid iteration
- Minimize context switching between tools
- Provide immediate feedback on changes
- Allow experimentation without heavy reconfiguration
- Example: Databricks’ notebook-centric workflow that scales to production
3. Meet users where they are
- Build SDK-first instead of UI-first
- Integrate with existing workflows (notebooks, CLI, etc.)
- Support multiple interfaces for different use cases
- Example: Netflix’s Papermill for productionizing notebooks
4. Focus on essential problems
- Solve data understanding challenges first
- Handle infrastructure concerns behind the scenes
- Provide sensible defaults with room for customization
- Example: Modern data warehouses abstracting away distribution complexity
The path forward
The future of data science tooling is about making complex infrastructure invisible while empowering users to solve real problems. We need tools that:
- Scale with complexity: Start simple, but support sophisticated use cases
- Enable collaboration: Make it easy for different roles to contribute
- Promote iteration: Support rapid experimentation and refinement
- Abstract wisely: Hide unnecessary complexity while maintaining power
Key takeaways for tool builders and users
For tool builders:
- Prioritize user workflow over infrastructure
- Build layered interfaces that grow with users
- Focus on reducing cognitive overhead
For practitioners:
- Evaluate tools based on iteration speed
- Look for solutions that scale with your needs
- Don’t accept unnecessary complexity
Data science will always involve complex problems. But our tools should help us tackle that essential complexity rather than adding accidental complexity. The next generation of data science tools must learn from Excel’s strengths while overcoming its limitations.
The best tool helps you solve real problems most effectively, not necessarily the most sophisticated one.
Is your data wicked?
If this post resonated with you, I would love to chat with you. Schedule a free consult to talk about how to tame your wicked data.