
You open the trace viewer. The scroll bar turns into a speck. Tool calls pile up like receipts. Somewhere in there the agent did three smart things, one catastrophically wrong thing, and then tried to fix it with confidence. You feel that pinch behind your eyes.
Here is how I make that feeling go away.
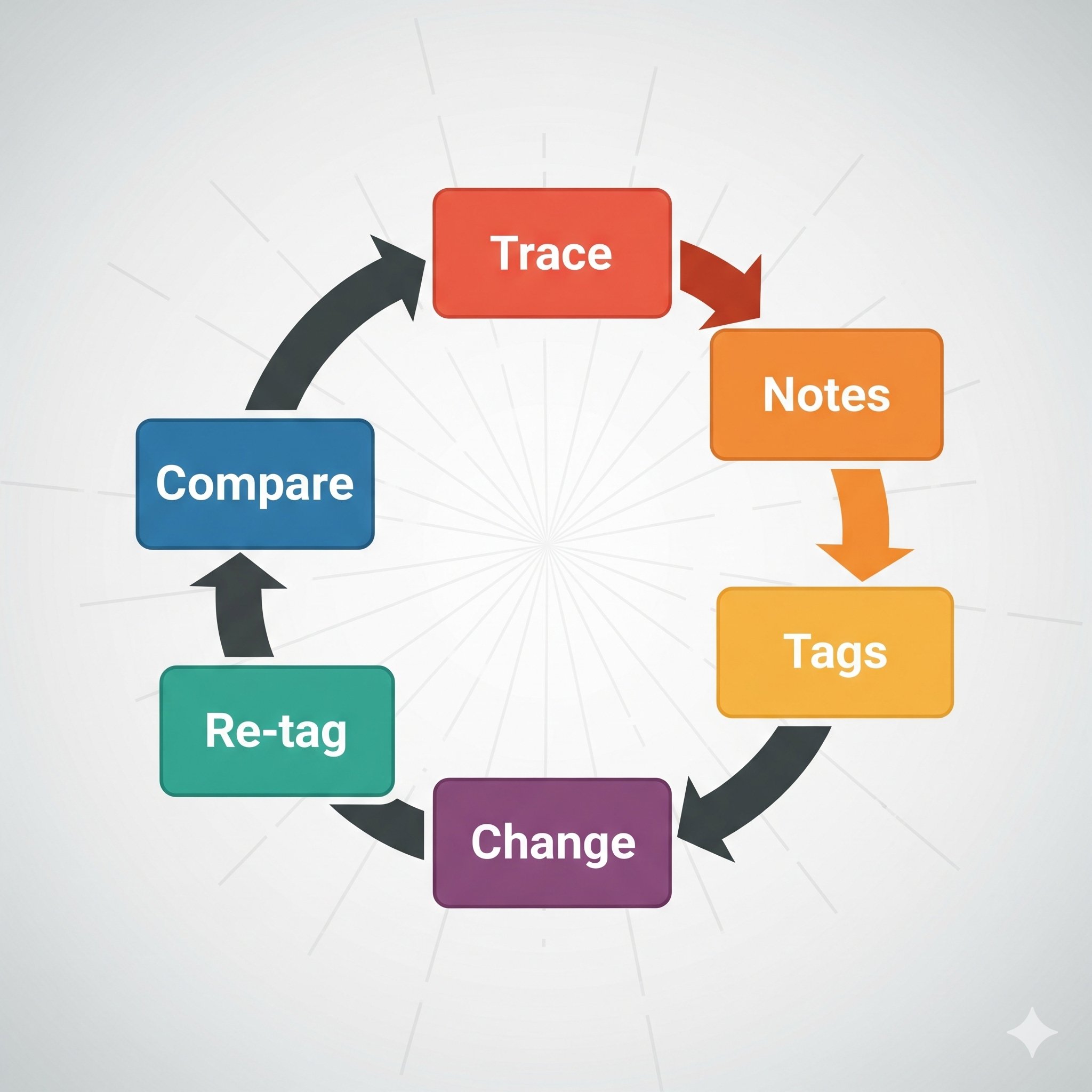
Start simple: the loop that never fails
Before we talk agents with tools and long conversations, we start with the humble loop I use for a single LLM call. The loop is boring. That is why it works.
- Look at traces. Pick a representative slice. Read them end to end.
- Write raw notes. Free text. No schema. Call out what you liked, what you didn’t like, what was weird in plain language.
- Turn notes into tags. Name the patterns. Keep the names crisp:
wrong_tool,lost_context_mid,bad_params,policy_violation,hallucinated_source. - Tag every trace. Manually at first.
- Make one targeted change. A prompt edit, a guard, a small tool fix.
- Re-tag the new traces. Same rubric.
- Compare. Did the tags move in the right direction without creating new pain?
This loop is my north star. I carry it forward when things get complicated.
Why multi-step hurts
Multi-step means long trajectories. Thought, tool, observe, repeat. There are often several valid paths from A to Z. The agent can succeed by going A to D to G to Z, or A to C to M to Z. That variety is good for users and tough for evaluators. Your trace is longer. The surface area for error is larger. One wrong step early can poison everything that follows.
Why multi-turn hurts even more
Now add the user as a moving part. A tweak that fixes one reply changes how the user responds two turns later. Offline replay stops being a clean mirror. You need a plan that respects the mess.
Keep the loop, add milestones
The process stays the same. We just shrink the unit of judgment.
Break the long trip into milestones. Think A to M, then M to Z. If each segment is correct, the whole thing is almost always correct. Your job becomes checking chunky checkpoints instead of squinting at a wall of tokens.
Example for a support agent, receiving a message “i can’t login”:
- Primary intent captured (e.g. login help)
- Information gathered (e.g. username or email)
- Evidence gathered from the right system (e.g. see failed login attempts)
- Remedy chosen within policy (e.g. reset password)
- Explanation and next step delivered (e.g. we’ve sent a reset link to your email)
Grade each one. Pass or fail. No vibes.

Composability matters
Design milestones so they compose. If you pass A→M and M→Z with the same input state, you should pass A→Z. That lets you swap implementations, compare versions, and keep your mental model clean.
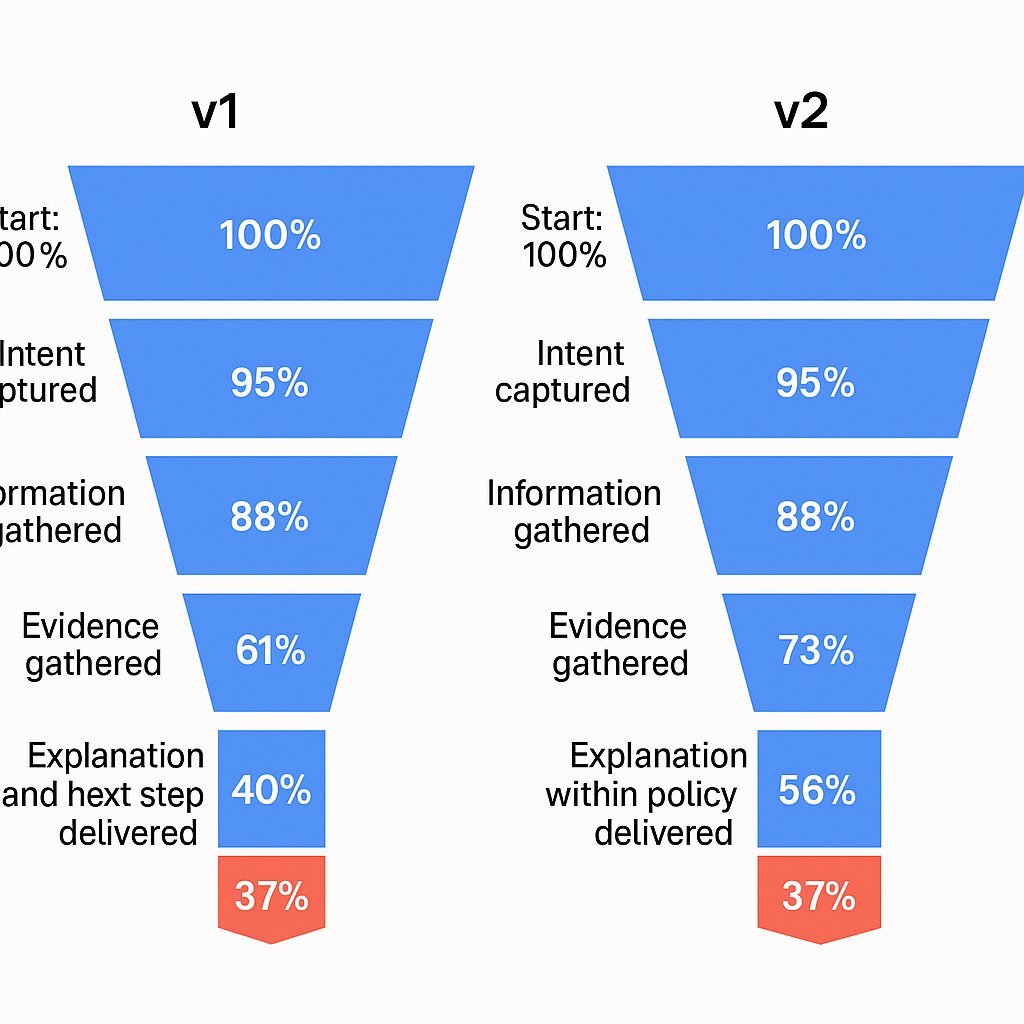
From milestones to failure funnels
Once you grade milestones across many traces, you can build a failure funnel. Where do runs die first, and how often?
- Start: 100%
- Intent captured: 95%
- Information gathered: 88%
- Evidence gathered: 61%
- Remedy within policy: 40%
- Explanation and next step delivered: 37%
Now we can clearly identify the biggest pain points.The leak is at evidence gathering and remedy selection. Fix there first. Then re-run the funnel and see if the shape changed.
Automate the tagging once it stabilizes
As you engage in this process, the tags (and milestones) will stabilize. At this point, you can teach a machine to automate the tagging process.
- LLM as a judge. Give it a tight rubric with yes or no checks for each tag. Calibrate with a few examples. Prefer pairwise comparisons when scoring quality.
- Classical classifiers. If tags map cleanly to structure in your logs, train small models. Fast, cheap, predictable.
Either way, you get tag distributions per version, per milestone, and per slice of traffic. Automated tagging enables:
- CI/CD gates: add information to PRs to verify that the code changes did not cause regressions
- Monitoring/Alerting: send alerts if significant changes in milestones
You will never escape the need to manually view and tag traces because:
- we need to ensure that the automated tagging is working correctly over time
- we need to identify new failure modes
So always retain a consistent practice of looking at your data and tagging!
The multi-turn wrinkle: users change the story
A change in one turn changes the users you get in the next. That makes offline testing brittle. You will still do it for speed, but expect to lean on online A/B tests for truth. Compare outcomes, funnels, and user signals like re-query rate or abandon rate. Do not try to compare turn by turn. Compare goals reached and where runs fell out of the funnel.
You can still expand your offline coverage in a smart way. Use your tag taxonomy to synthesize specific behaviors you see in production. An example I test often:
- The user complains about not being able to login
- The agent helps the user reset their password
- The user immediately pivots to a new, unrelated question
If that pivot shows up in your tags, you can script it. Your simulator does not need to be perfect. It just needs to reproduce the behaviors that hurt you most.
Niche down to move fast
Do not try to decompose the entire product on day one. Pick a slice and go deep. Which slice? It depends on your product! Look through a representative sample of traces to identify the most common queries or the most annoying issues. Focusing on that one thing will give you a lot of bang for your buck. And it’s totally okay if it’s not the “perfect” slice to start with! You’ll expand into new slices very soon.
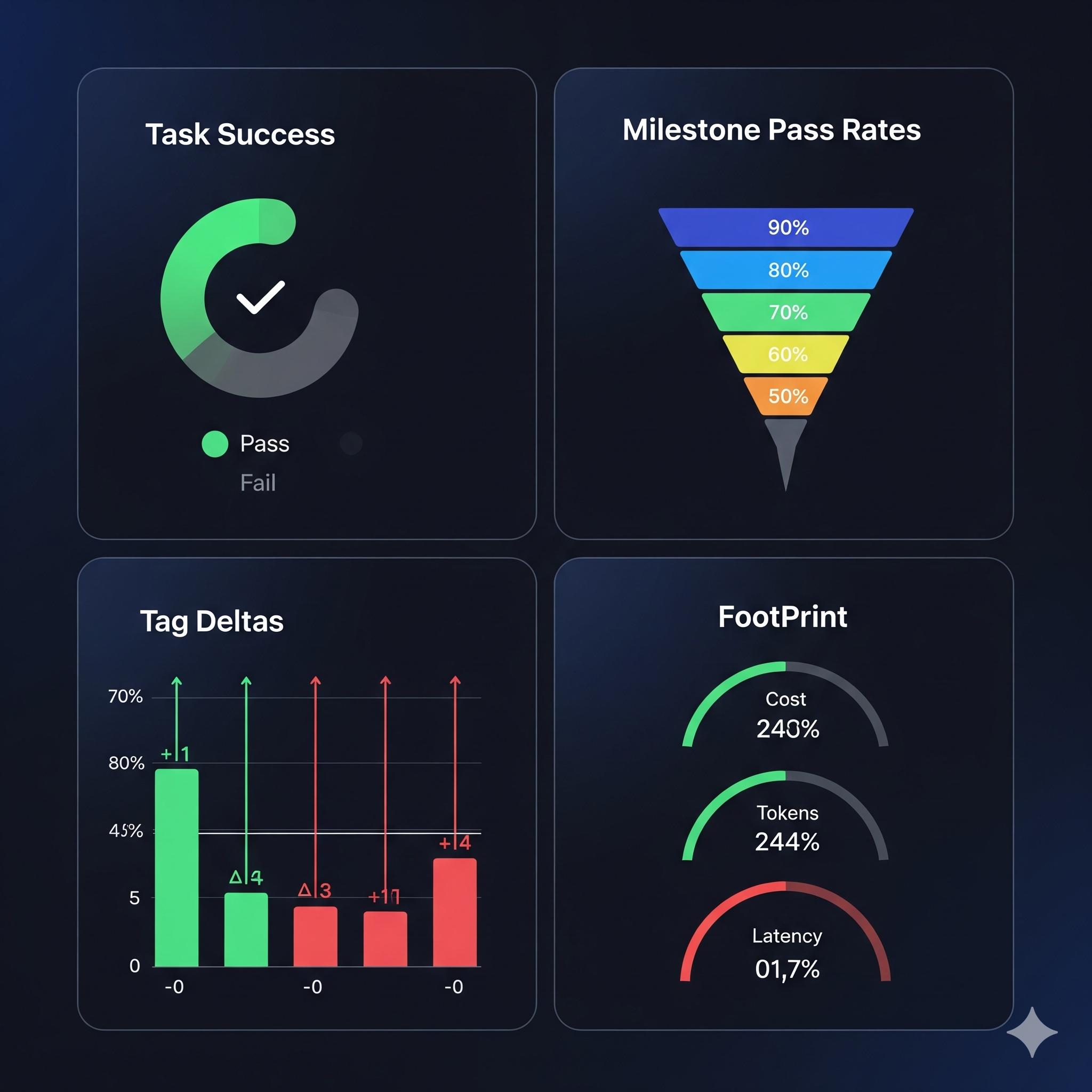
Put it all together: a scoreboard you can trust
Every release gets the same four boxes:
- Task success: pass or fail at the goal
- Milestone pass rates: funnel shape and first failure
- Tag deltas: which pains went down, which popped up
- Footprint: cost, tokens, latency
No single number. No mystery. Just a view that respects tradeoffs.
A quick story
We launched a billing agent that looked fine in a demo and felt wrong in production. Success sat at 42 percent. Users were irritated.
Milestones made the pattern obvious. Authentication passed 95 percent. Intent capture passed 88 percent. Evidence gathering dropped hard. Remedy selection dropped harder. Tags pointed at bad_params and policy_violation during the refund step. One malformed amount field when taxes were present. Fixing the argument builder and adding a strict schema check bumped success to 58 percent. Latency ticked up a hair. The funnel confirmed the leak was sealed.
That is the rhythm. Find the leak. Patch the leak. Verify with the same eyes and the same rubric.
Why this approach sticks
Long traces stop being fog. Milestones give you handles. Tags give you shared language. Funnels give you focus. Automation gives you speed. A/B tests give you reality.
You end up with a system that gets better in small, honest steps. Fewer mystery wins. Fewer surprise losses. More trust from users who feel the difference.
And you get your scroll bar back.
Want help implementing this process? Book a free consult