GPT-5.4 in OpenClaw doesn’t suck. Your prompts do.
/ 6 min read
Table of Contents
Anthropic changed the rules for OpenClaw.
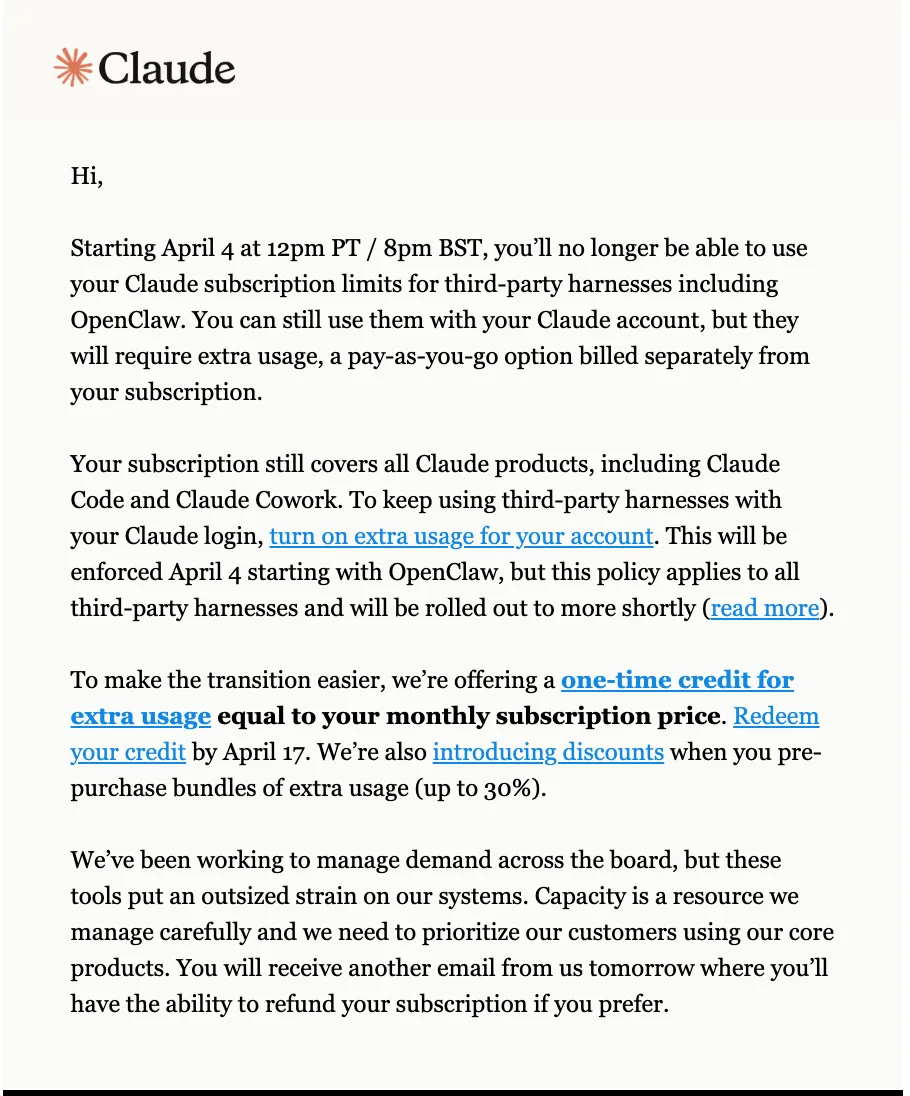
Starting April 4 at 12pm PT, Claude subscription limits no longer apply to third-party harnesses including OpenClaw. You can still use Claude. You just have to pay for extra usage on top of your subscription.
That’s the whole problem.
Opus has always had the best vibes in OpenClaw. The subscription made that easy to justify. But once you move to usage pricing, the math gets ugly fast.
So the panic makes sense.
The bad conclusion is: GPT-5.4 just isn’t good enough.
My conclusion is different:
GPT-5.4 in OpenClaw doesn’t suck. Your prompts do.
What actually changed
Anthropic’s email says:
- Claude subscription limits no longer apply to OpenClaw
- Claude Code and Claude Cowork are still covered
- OpenClaw now requires extra usage
- Anthropic is offering a one-time credit
- Anthropic is offering up to 30% prepaid bundle discounts
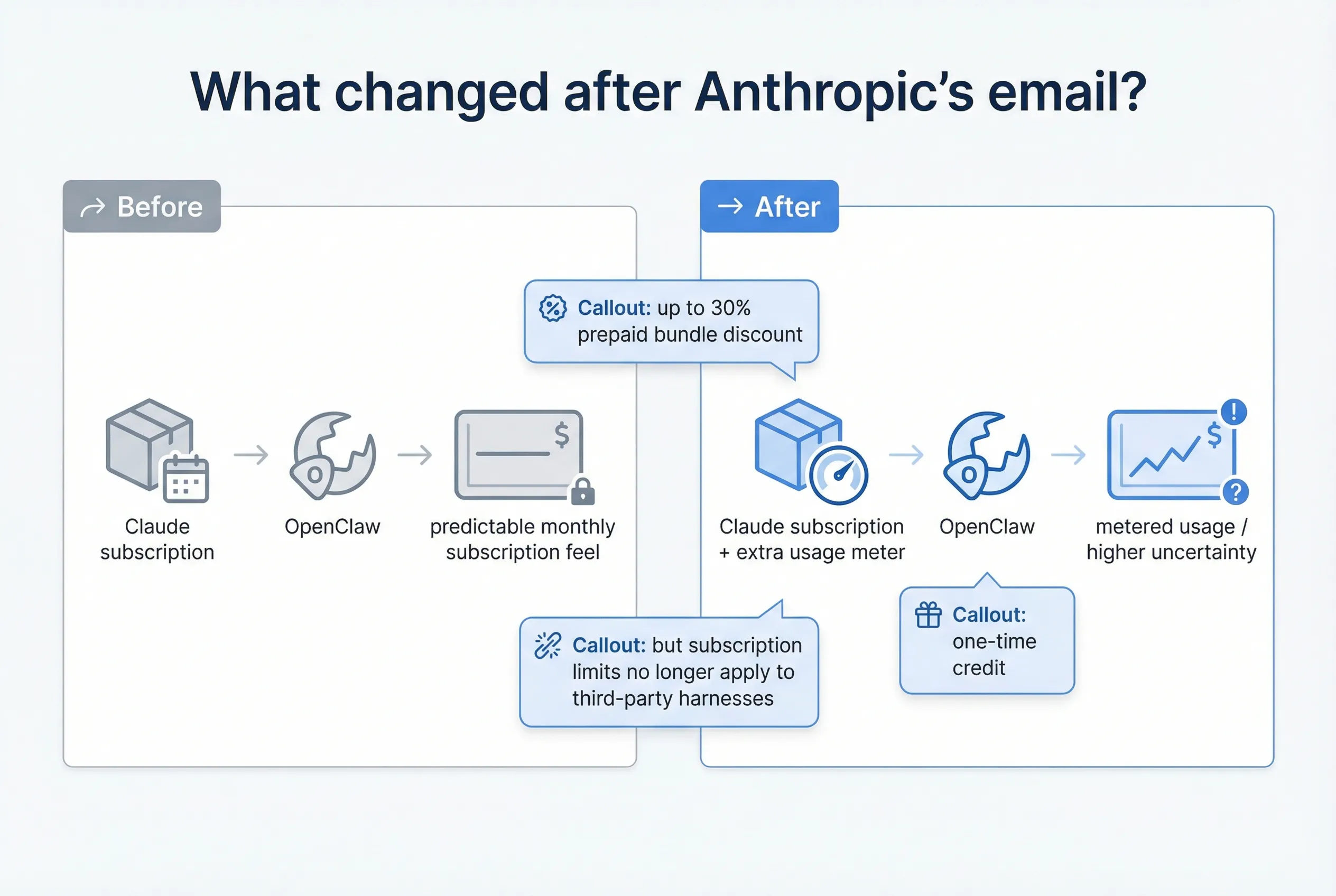
That means the debate changed.
It’s no longer just Opus vs GPT. It’s also subscription pricing vs usage pricing.
Why people are suddenly looking at GPT
OpenAI still supports a subscription-backed path through ChatGPT / Codex.
OpenAI’s docs say:
- Sign in with ChatGPT gives subscription access
- Every ChatGPT plan includes Codex
codex login --device-authworks for remote boxes
That matters more than benchmark tribalism.
A lot of users are not choosing between two abstract models. They’re choosing between:
- “this still feels like a subscription”
- and
- “this can quietly become an infra bill”
The real mistake people are making
I keep hearing the same complaint:
“GPT is substantially dumber than Claude in an OpenClaw context.”
I get it.
But most people are not testing GPT-5.4 fairly.
They’re taking prompts and bootstrap files that were tuned around Claude behavior, swapping the model name, and calling that an eval.
That’s not an eval. That’s a setup mismatch.
The framing from One Soul, Many Minds is right:
- same soul
- same mission
- same personality
- different overlay per model
You do not need a different assistant. You probably do need different prompting.
The public benchmark story is mixed
That’s a good thing.
Public comparisons suggest:
- Opus still looks very strong on broad coding / agentic work
- GPT-5.4 looks good on Terminal-Bench 2.0
- GPT-5.4 looks good on MCP Atlas
- GPT-5.4 looks good on OSWorld
- GPT-5.4 is cheaper on API pricing
So no, I’m not saying GPT-5.4 is better than Opus.
I’m saying this:
GPT-5.4 is too capable to dismiss, and too cheap to ignore.
We ran our own evals
I didn’t want to rely on internet takes, so I built a small eval setup around the kinds of work I actually use OpenClaw for.
The eval categories were:
- Newsletter writing
- Coding
- Polish / planning
- Heartbeat
- Personality
Each eval had 5 samples and 5 scoring criteria for a total of 25 points.
Before tuning vs after tuning
Here’s the part that matters.
Before tuning
| Eval | GPT-5.4 | Opus 4.6 |
|---|---|---|
| Newsletter writing | 10/25 | 18/25 |
| Coding | 20/25 | 20/25 |
| Polish / planning | 17/25 | 20/25 |
| Heartbeat | 15/25 | 23/25 |
| Personality | 11/25 | 22/25 |
After tuning
| Eval | GPT-5.4 | Opus 4.6 |
|---|---|---|
| Newsletter writing | 20/25 | 18/25 |
| Coding | 22/25 | 20/25 |
| Polish / planning | 18/25 | 20/25 |
| Heartbeat | 22/25 | 23/25 |
| Personality | 23/25 | 22/25 |
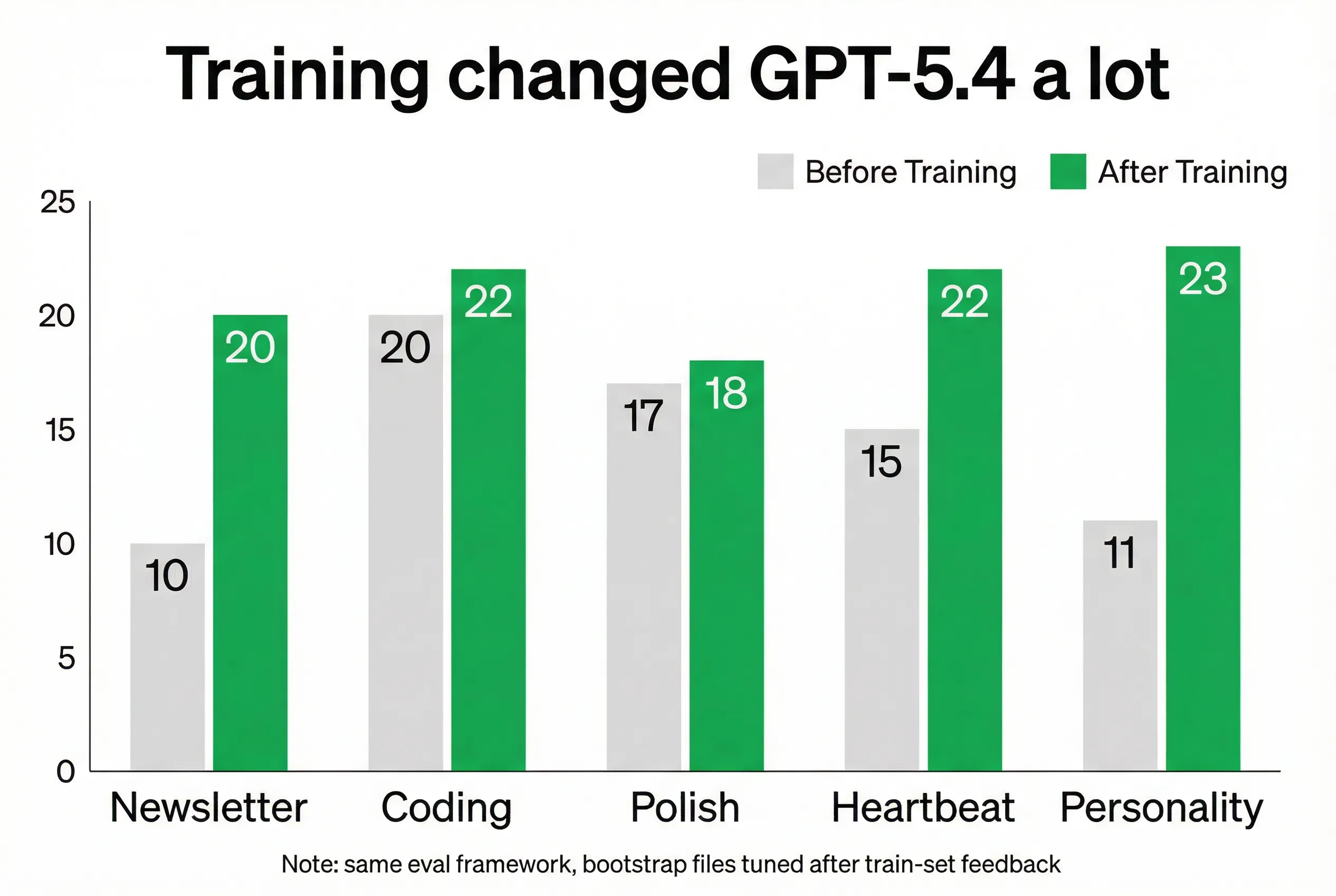
That is the whole story.
GPT-5.4 looked much worse before tuning. It got dramatically better after tuning.
Not because the model changed. Because the setup changed.
What changed during tuning
I ran a train / validation loop:
- run prompts
- review outputs
- give feedback
- rewrite bootstrap files
- run again
The main files I tuned were:
SOUL.mdAGENTS.mdHEARTBEAT.md- supporting instruction files
The big GPT-5.4 failure modes were:
- weaker vibes by default
- more sensitivity to conflicting instructions
- more likely to miss the intended tone
- more likely to explain instead of execute
Once I tuned for those, the gap shrank a lot.
In some categories, GPT-5.4 actually pulled ahead.
How I’d switch an OpenClaw setup today
1) Use the ChatGPT / Codex path
OpenAI supports:
- ChatGPT sign-in for subscription-backed access
- API keys for usage-based access
Useful links:
- ChatGPT pricing: https://openai.com/business/chatgpt-pricing/
- Codex auth: https://developers.openai.com/codex/auth
- Codex pricing: https://developers.openai.com/codex/pricing
2) Use device auth on a remote machine
codex login --device-authThat’s the cleanest path if you’re on a remote box.
3) Keep the soul, change the overlay
Don’t rewrite your assistant from scratch.
Keep the identity. Keep the mission. Keep the voice.
Change the instructions that shape execution.
For GPT-5.4, that usually means pushing harder on:
- brevity
- decisiveness
- execution over explanation
- less sycophancy
- clearer instruction hierarchy
Make your own evals
This is the part I’d recommend to almost everyone.
Don’t rely on my use cases. Build your own.
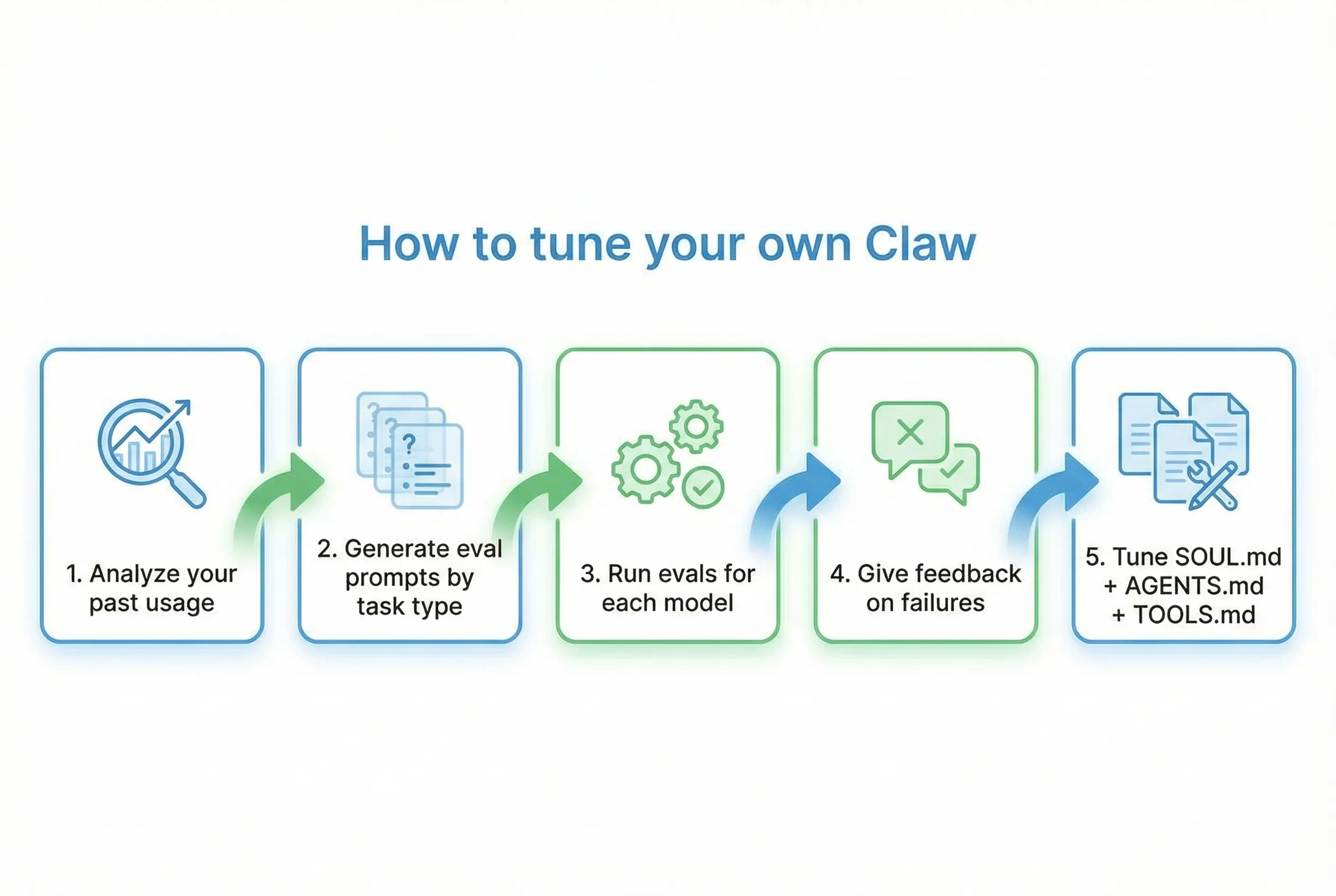
The workflow
- identify your main task types
- create prompts for each task type
- run the evals on each model
- review the failures
- tune your bootstrap files
Prompt 1: identify your task types
I want to build model-tuning evals for my OpenClaw setup.
Please analyze my recent usage and identify the main categories of work I actually use this claw for.
Your job:1. Infer the 5-8 most important task categories based on actual usage, not generic assumptions.2. For each category, describe: - what the task type is - why it matters - what “good” looks like - common failure modes3. Rank them by importance/frequency.4. Suggest which categories are best for model evals.5. Be opinionated. Merge overlapping categories. Don’t give me fluff.Prompt 2: generate the eval prompts
Using the task categories we identified, create a small eval suite for my claw.
Your job:1. Create a folder structure for the evals.2. For each selected task category, create 3-5 representative prompts.3. Include a short README for each category explaining what this category is testing and what failure modes to watch for.4. Save everything in a clean folder structure.
Important constraints:- Use realistic prompts- Test real task behavior, not benchmark trivia- Include some ambiguity and judgment- Avoid repetitive promptsPrompt 3: run the evals
I want to run my eval suite against a specific model.
Model to use: [INSERT MODEL NAME]
Please:1. Find the eval prompts in my eval folder.2. Run each prompt using the specified model.3. Save outputs in a parallel folder structure so I can compare results later.4. Include the original prompt, model used, and output in each file.5. Do not grade anything yet. Just run the evals cleanly.Prompt 4: tune the bootstrap files
I ran model evals and reviewed the results. Now I want to tune my claw’s bootstrap files.
Files to review:- SOUL.md- AGENTS.md- TOOLS.md- any other relevant operating files
Your job:1. Read the eval feedback and identify recurring failure modes.2. Decide which problems belong in SOUL.md, AGENTS.md, and TOOLS.md.3. Suggest concrete edits.4. Explain why each edit addresses a specific failure.5. Preserve the core personality and intent of the assistant.6. Do not rewrite everything. Make targeted, high-leverage changes.The conclusion
If you swap Opus for GPT-5.4 and change nothing, there’s a good chance GPT will feel worse.
That does not mean GPT-5.4 is bad in OpenClaw. It means you ran a lazy test.
What my evals showed is simple:
- Opus is still excellent
- GPT-5.4 gets much better after tuning
- the gap is smaller than people think
- in some workflows, GPT-5.4 can absolutely win
So if Anthropic’s pricing change pushed you toward GPT, don’t just flip the model and complain.
Retune the setup. Run evals on your real use cases. Then decide.
The results may surprise you!