Introduction: The Challenge of Improving AI Systems
Improving AI systems is hard. Unlike traditional software where you can often directly observe and fix bugs, AI systems present unique challenges:
- Performance issues are often subtle and multi-faceted
- The relationship between changes and improvements isn’t always clear
- The development cycle can be slow and resource-intensive
- It’s easy to chase improvements that don’t materially matter
I have built many AI systems and teams to build AI systems over my career. The best AI engineers always follow a similar systematic process; but it also seems there is a dearth of examples of what that might look like in practice. In this post, I’ll walk through a real example of improving an AI system, showing both what worked and what didn’t. We’ll look at how to build the infrastructure and processes needed to make systematic improvements.
Example Project
We’ll be working with a project planning system that takes informal project descriptions and converts them into structured plans with tasks and durations. I start with a small set of real examples:
project_inputs = [
"Help me throw a party to celebrate Erik and his fiancee Sheila getting jobs...",
"I want to record my grandparents lifestories in some kind of format...",
"I want to take Shreyas Doshi's Product Sense course...",
# ... additional examples
]This is a tool that would be helpful for me in day to day life. I often create projects in project management software, but it always starts as disorganized thoughts in my head. This would let me go more quickly from idea to plan.
Development Setup
I’m using several tools to help manage the development process:
- Mirascope: A framework for building LLM applications that provides:
- Type-safe LLM function calls
- Structured output / response validation
- Error handling
- Custom Logging Middleware: Built using Mirascope’s middleware system to track:
- Input prompts
- Model responses
- Errors and metadata All stored in a SQLite database for easy analysis
Here’s how the basic setup looks:
@with_response_logging()
@llm.call(provider='openai', model='gpt-4o-mini', response_model=Project)
@prompt_template(system_prompt)
def plan_project(project_notes: str): ...Check out mirascope to use in your own projects!
Starting Point: Understanding Current Performance
The first step in any improvement process is understanding where you are. I need data about the system’s current performance, but what data should I collect?
Initial Data Collection Approaches
I explored two parallel approaches to data collection:
Spreadsheet Analysis: Quick exports of basic metrics:
- Project name
- Task count
- Total duration
- Task breakdowns
Spreadsheets are often great because everyone knows how to use them and it’s usually easy to export from any system to a spreadsheet compatible format (e.g. CSV). However, custom annotation UIs are often more flexible and allow you to avoid context switching as much.
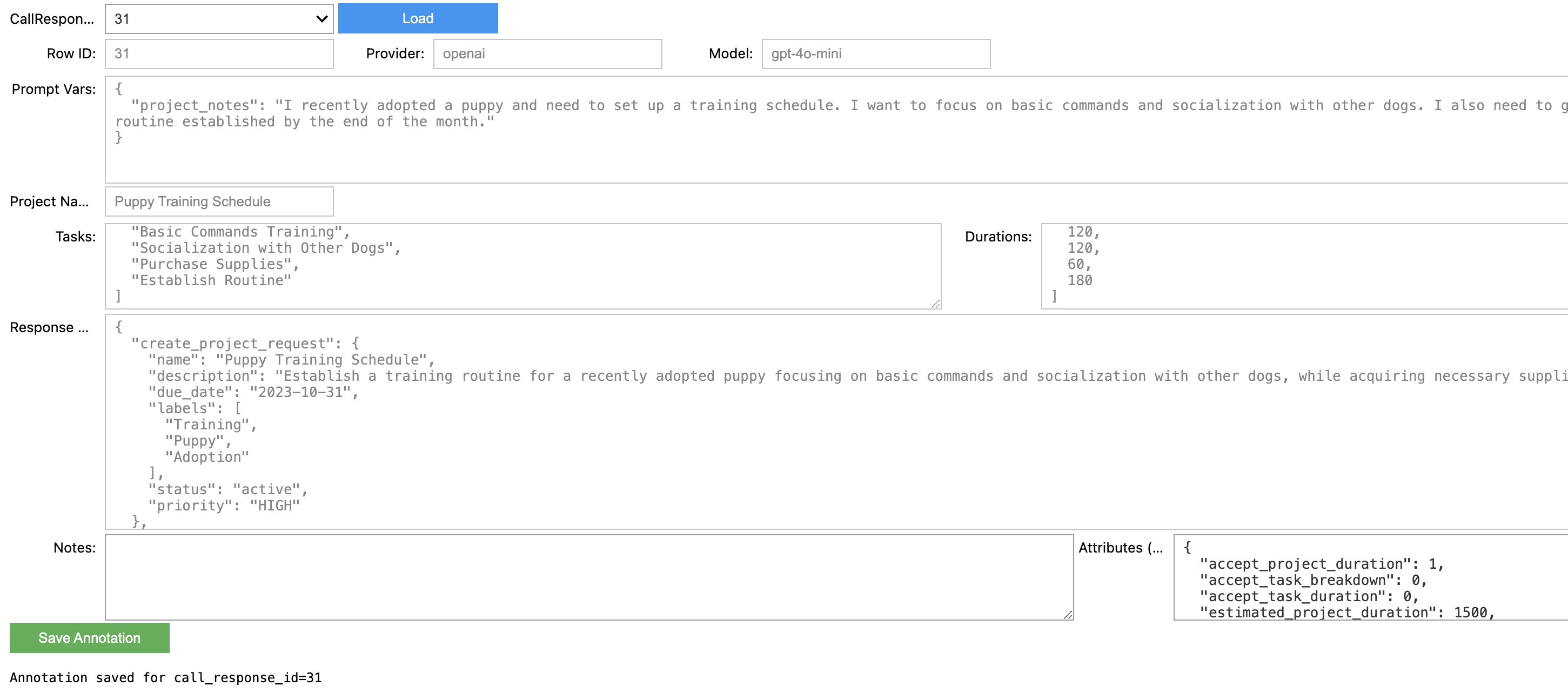
Custom Annotation UI: A Jupyter-based UI for more detailed analysis:
def create_annotations_ui(query=None): with Session(engine) as session: # UI components for viewing and annotating results call_response_dropdown = widgets.Dropdown( options=id_choices, description="CallResponse ID:" ) text_notes = widgets.Textarea( description="Notes:", layout=widgets.Layout(width='50%', height='80px') ) # ... additional components
The UI approach won out because it let us: - Easily view full context - Add structured and unstructured annotations - Track versions - Query and analyze results - Easy to create with AI coding tools like Cursor.
Here’s what it looked like:
Developing an Evaluation Framework
After examining the initial examples, I noticed recurring issues:
- Total project durations were often unrealistic
- Task breakdowns varied wildly in quality
- Individual task durations didn’t align with reality
I had several ideas for evaluating the system:
- Compare against actual project completions (rejected: no ground truth data available)
- Use expert estimates as benchmarks (rejected: too time-consuming to gather)
- Binary acceptability judgments (chosen: quick to annotate, clear to interpret)
- Relative rankings of outputs (rejected: too complex for my needs)
I settled on three binary metrics:
{
"accept_project_duration": 0, # 0 or 1
"accept_task_breakdown": 0, # 0 or 1
"accept_task_duration": 0 # 0 or 1
}SQL query to track progress:
SELECT
avg(accept_project_duration) as avg_accept_project_duration,
avg(accept_task_breakdown) as avg_accept_task_breakdown,
avg(accept_task_duration) as avg_accept_task_duration
FROM annotations
WHERE version = '{v}'Iterative Improvement Process
1. Basic Task Structure (v0.0.4)
The first version focused on basic functionality. Results were poor:
- Project Duration Acceptance: 23%
- Task Breakdown Acceptance: 7.7%
- Task Duration Acceptance: 7.7%
I considered several improvements:
- Add example-based prompting (rejected: too much variance in examples)
- Add system-level constraints (implemented)
- Add reasoning steps (planned for next iteration)
- Use a larger model (rejected: wanted to exhaust simpler options first)
2. Adding Reasoning (v0.0.5)
Added explicit reasoning to help the model think through project structure:
class Project(BaseModel):
reasoning_traces: list[str]
create_project_request: ProjectCreateRequest
create_project_tasks_request: list[CreateProjectTaskRequest]Results were mixed: - Project Duration Acceptance: 34.3% (↑) - Task Breakdown Acceptance: 47.2% (↑) - Task Duration Acceptance: 23.8% (↑) But variance increased significantly.
Considered improvements: 1. Add more structure to reasoning (rejected: made outputs worse) 2. Add completion criteria (implemented in later version) 3. Add task dependencies (rejected: added complexity without clear benefit) 4. Constrain durations (implemented next)
3. Structured Duration Constraints (v0.0.6)
Added fixed duration options:
duration: int = Field(
description="Number of minutes the task should take. Stick to: 15, 30, 60, 120, 240, 480, 960"
)Results stabilized: - Project Duration Acceptance: 52.4% - Task Breakdown Acceptance: 33.3% - Task Duration Acceptance: 38.9%
Additional ideas explored: 1. Add duration examples (implemented but didn’t help) 2. Add project categorization (planned for future) 3. Add task templates (rejected: too rigid) 4. Add research steps (implemented in prompt)
Expanding the Dataset
When progress plateaued, I needed more data. Options considered: 1. Gather more real examples (rejected: too slow) 2. Use synthetic data (implemented) 3. Modify existing examples (rejected: not enough variation) 4. Crowdsource examples (rejected: quality concerns)
I implemented synthetic data generation:
@with_response_logging()
@llm.call(provider='openai', model="gpt-4o-mini",
response_model=SyntheticProjectNotes)
def generate_synthetic_project_notes(
example_projects_notes: list[str]
): ...This revealed new challenges: - Domain-specific knowledge gaps - Handling of fixed-duration events - Variable task duration estimation
Final Results and Key Learnings
After 7 iterations: - Project Duration Acceptance: 76.9% - Task Breakdown Acceptance: 92.3% - Task Duration Acceptance: 76.9%
Key insights about evaluation-driven development:
- Data Requirements
- Single examples rarely provide enough signal
- Need multiple examples of each failure mode
- Synthetic data helps but must be realistic
- Evaluation Evolution
- Start broad with unstructured notes
- Move to structured evaluation as patterns emerge
- Be willing to revise criteria
- Technical Infrastructure
- Start simple (spreadsheets are fine!)
- Add complexity only when needed
- Version everything
Practical Tips for Teams
The journey of improving an AI system is as much about process and culture as it is about technical changes. Teams that succeed in this space typically excel at three things: documentation, experimentation, and learning from failure.
Documentation
- Standardize experiment logs
- Track hypotheses and results
- Make information discoverable
Experimentation
- Start with simple tools
- Make iteration cycles fast
- Build on what works
Learning Culture
- Document failed approaches
- Share insights across teams
- Maintain systematic processes
Conclusion
The key to improving AI systems is having a clear, data-driven approach to measuring progress. The process isn’t always fun - manual data annotation can be tedious, and many promising ideas will fail to help. But it’s these unglamorous aspects of AI development that often provide the biggest competitive advantages.
Looking for help applying this process to your own projects? Book a free consult.