A Systematic Approach to Building Reliable Agent Systems
Skylar Payne
AI is Fundamentally Empirical
We can’t predict what will work.
LLMs are highly data-dependent
Performance varies wildly across use cases
We have priors (educated guesses)…
…but we must experiment to find out
The Challenge: Understanding
Long-running agents are hard to evaluate:
Cost: Running full eval suites gets expensive fast ($10-50 per test run)
Latency: Multi-turn conversations take 30s-5min to execute
Context Overload: Which of the 47 steps actually broke?
Why This Matters
If we can’t evaluate agents systematically:
We can’t understand when/why they fail
We can’t improve them reliably
We can’t maintain them as requirements change
We can’t ship them with confidence
The solution: Make evaluation straightforward through systematic decomposition.
What We’ll Cover Today
The Framework: Evaluation pyramid and decomposition strategies
Implementation: Code design, tracing, and system evaluation
In Practice: Real results and research validation
Part 1: The Framework
Evaluation Pyramid & Decomposition
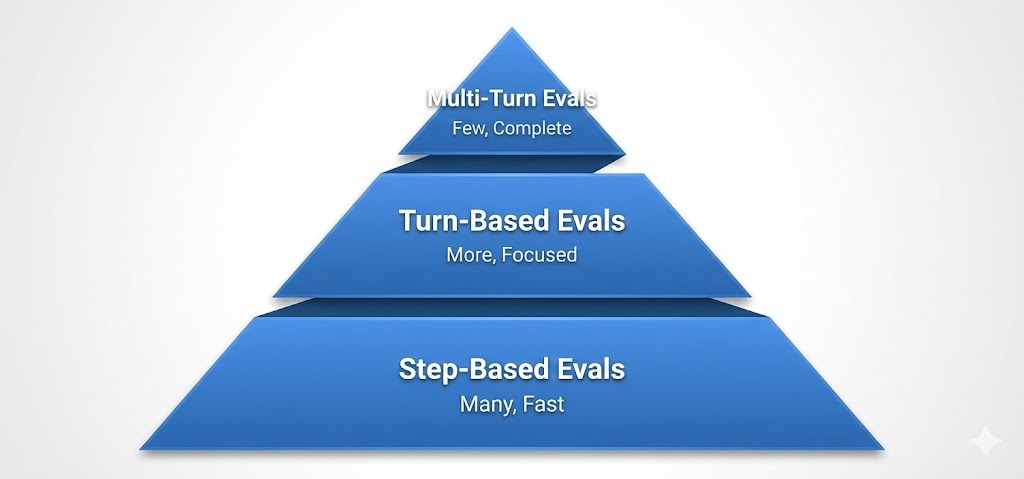
The Evaluation Pyramid
Not all evals are created equal:
Principle: Test narrow/fast at the bottom, broad/slow at the top
Step-Based Evals: The Foundation
Test individual components in isolation:
Tool calls: “Did it call the right function?”
Parameter extraction: “Did it parse user input correctly?”
Domain logic: “Did it apply business rules?”
Validation: “Did it catch invalid inputs?”
Why: Fast feedback (<1s), easy to debug, cheap (<$0.01)
Step-Based Eval: Code Example
def test_extract_contact_info():"""Test that we correctly extract email from user message""" message ="Please email me at sky@example.com" result = extract_contact_info(message)assert result.email =="sky@example.com"assert result.has_contact_method ==True
Fast, deterministic, easy to debug
Turn-Based Evals: The Middle Layer
Test single-turn interactions:
User message → Agent response
Check partial ordering of tool calls
“Read must happen before write”
“Verify identity before granting access”
Validate tool parameters and response quality
Why: Catches integration issues, still relatively fast (~5-10s per test)
Turn-Based Eval: Code Example
def test_handle_refund_request():"""Test agent correctly handles refund request""" conversation = Conversation() response = agent.handle_turn( conversation, user_msg="I need a refund for order #12345" )# Check it called the right toolassert response.tool_calls[0].name =="lookup_order"assert response.tool_calls[0].args["order_id"] =="12345"# Check response qualityassert"refund"in response.message.lower()assert response.needs_user_confirmation ==True
Multi-Turn Evals: The Challenge
Test complete conversations:
Full user journey from start to finish
Simulate the user - respond to agent naturally
Multiple turns of interaction
Context accumulation across turns
Did the agent achieve the user’s goal?
Problem: Expensive ($1-5 per test), slow (30s-5min), hard to debug
Solution: Break into milestones
Milestones: Decomposing Multi-Turn
Instead of: Did the conversation succeed? ✅/❌
Ask: What are the critical checkpoints for this user flow?
Intent captured?
Necessary info gathered?
Tool executed successfully?
Policy compliance checked?
Response delivered clearly?
Key insight: Milestones are user-flow specific - different flows need different checkpoints
Track milestone completion rates across many runs:
Biggest drop = highest leverage fix
Failure Funnel: Real Example
Password Reset Flow - Initial deployment:
The funnel showed 28% drop at remedy selection
Problem: Agent chose “unlock account” when should send reset link
Root cause: Ambiguous phrasing in account status tool response
Fix: Clarified tool output format + added examples
Result: 42% → 70% overall success rate
Don’t fix everything - fix the biggest leak first
Part 2: Implementation
Code Design, Tracing, & System Evaluation
Code Design for Testability
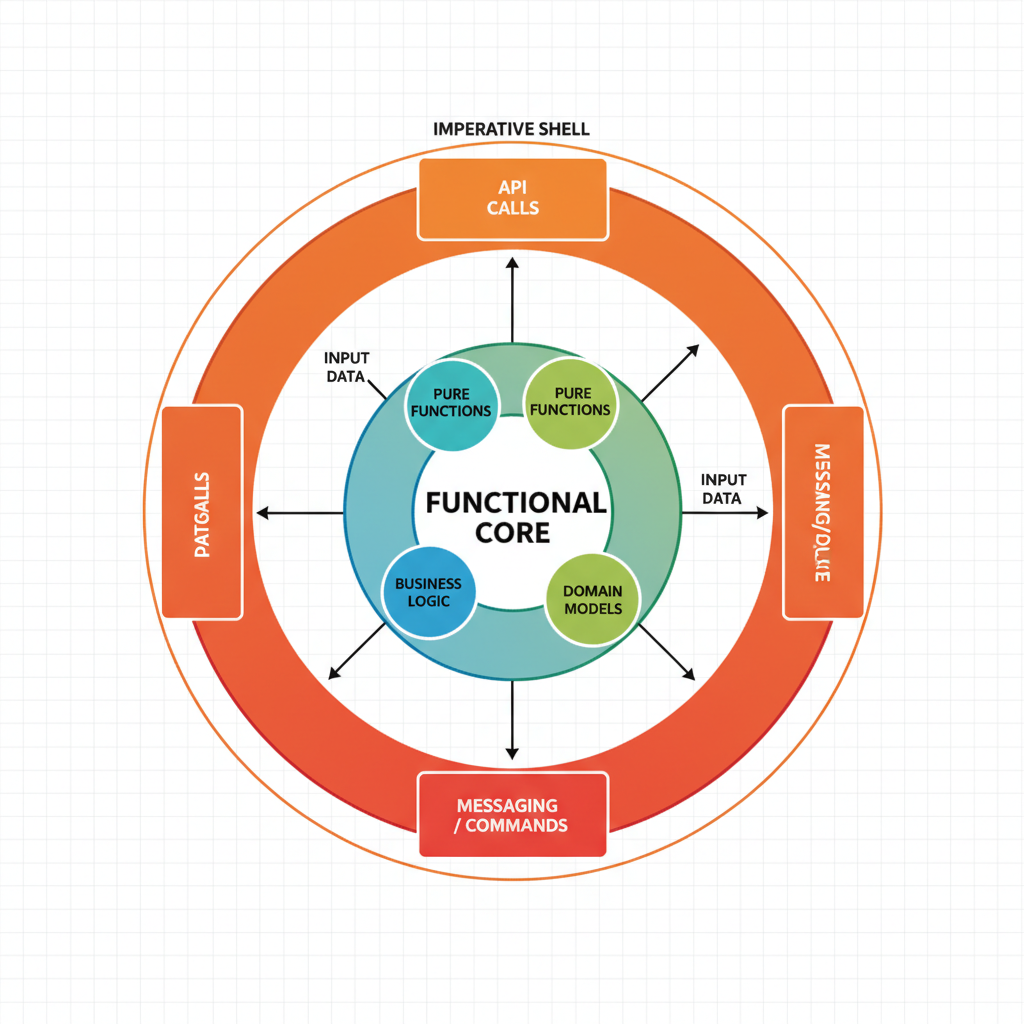
Functional Core, Imperative Shell
Functional Core
Pure functions
No I/O or LLM calls
Deterministic
Easy to test
Imperative Shell
API calls
Database writes
LLM invocations
Thin layer
Result: 80% of your code is fast to test with step-based evals
Before: Tangled Code
asyncdef handle_refund(user_message: str):"""Everything tangled together - hard to test"""# LLM call embedded in business logic response =await llm.complete(f"Extract order ID from: {user_message}" ) order_id = response.text.strip()# Database call embedded order =await db.get_order(order_id)# Business logic mixed with I/Oif order.amount >100:await db.create_refund(order_id, order.amount)return"Refund processed"else:return"No refund needed"
Problem: Can’t test business logic without LLM/DB
After: Functional Core + Imperative Shell
# CORE: Pure function, easy to testdef should_process_refund(order: Order) -> RefundDecision:"""Business logic - no I/O"""if order.amount >100:return RefundDecision( approve=True, amount=order.amount, reason="Amount exceeds threshold" )return RefundDecision(approve=False, reason="Below threshold")# SHELL: Thin layer for I/Oasyncdef handle_refund(user_message: str):"""Orchestration - delegates to core""" order_id =await extract_order_id(user_message) # LLM order =await db.get_order(order_id) # DB decision = should_process_refund(order) # CORE - pure!if decision.approve:await db.create_refund(order_id, decision.amount) # DBreturn format_response(decision) # Pure formatting
Functional core and imperative shell architecture
Testing the Functional Core
def test_refund_decision_above_threshold():"""Fast, deterministic, no mocks""" order = Order(id="123", amount=150) decision = should_process_refund(order)assert decision.approve ==Trueassert decision.amount ==150assert"threshold"in decision.reasondef test_refund_decision_below_threshold(): order = Order(id="456", amount=50) decision = should_process_refund(order)assert decision.approve ==False
Runs in milliseconds. No LLM. No database. No mocks.