10x Your RAG Evaluation
by Avoiding these Pitfalls
2025-07-30
The Problem
RAG systems fail silently, and teams struggle to debug them.

- “answer looks wrong” provides no actionable debugging path
- Silent failures accumulate as technical debt
- Teams waste time guessing what’s broken
Goal: Build systematic evaluation into your RAG pipeline
About Me

Empowering you to build AI products users love.
And permanently ditch those 3 AM debugging sessions.
- Building AI products for over a decade at Google, LinkedIn, and in AI based diagnostics (healthcare)
- Trained over 100 engineers to build AI products
- Hands on executive experience building the teams that build AI products
Fun fact: my favorite movie is Mean Girls (I have a party for it every October 3rd).
Pitfall #1: Corpus Coverage
Do we have all the documents we need?
Use case: "How do I integrate with Salesforce?"
Search results: 0 relevant chunks
Reality: Integration exists but no docs were written
The cost: Lost customers who assume you don't support their stackEvaluation Test:
Measure % of queries that return relevant chunks across your entire corpus

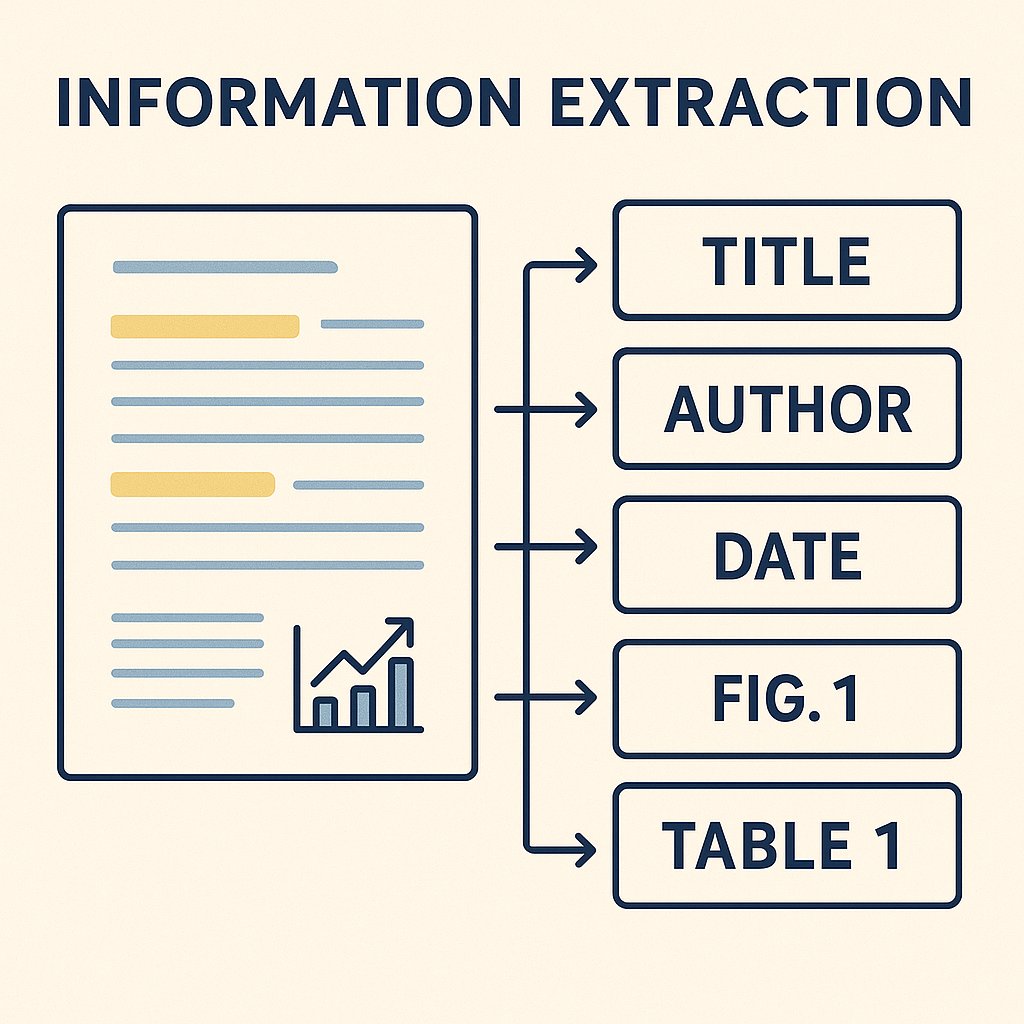
Pitfall #2: Information Extraction
Do we understand the content well enough?
Bad format:
"See attached PDF for API documentation (link broken)"
Good format:
"API Authentication: Use Bearer tokens in the Authorization header.
Example: Authorization: Bearer your_token_here"Evaluation Test:
Verify tables, code blocks, and structured data are correctly parsed/extracted
Pitfall #3: Chunk Quality
Meaningful chunking that balances relevancy?
Bad chunking:
Chunk 1: "To set up authentication, first install the SDK"
Chunk 2: "Then configure your API key in the dashboard"
Chunk 3: "Finally, add the auth middleware to your app"
Good chunking:
Chunk 1: "Authentication Setup:
1. Install SDK: npm install our-custom-sdk
2. Configure API key in dashboard
3. Add auth middleware to your app"Evaluation Test:
Look at samples of large chunks, small chunks, frequently retrieved, and rarely retrieved chunks

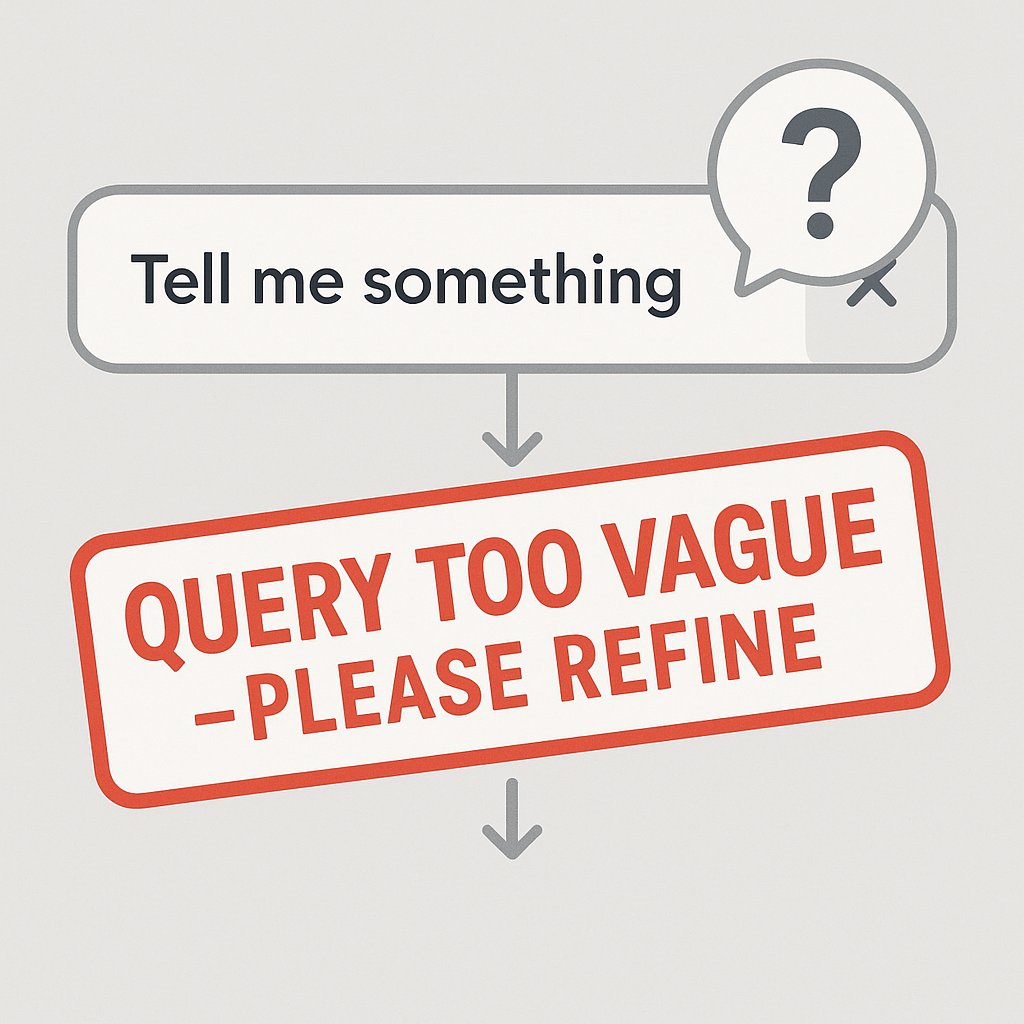
Pitfall #4: Query Rejection
Was the query well-formed?
Unclear query: "thing broken"
Clear query: "Why is my API authentication failing with 401 error?"
Unclear query: "pricing info"
Clear query: "What are the pricing tiers for enterprise customers?"Evaluation Test:
Calculate rejection rate and elicitation rate for unclear queries
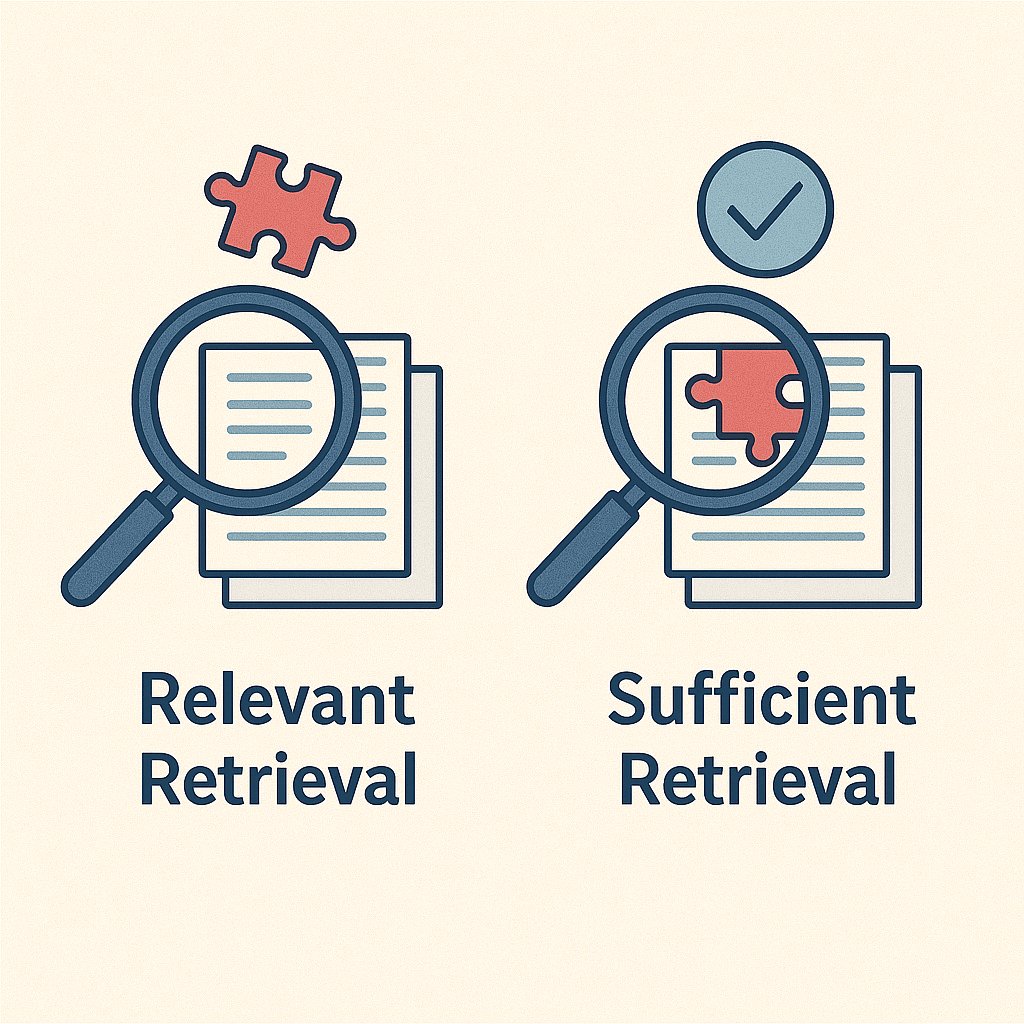
Pitfall #5: Retrieval Sufficiency
Did we get enough relevant docs?
Query: "How do I implement user segmentation?"
Retrieved chunks:
- "User segmentation allows personalized experiences" ✓ relevant
- "Create segments based on user behavior" ✓ relevant
- "Segments can be used for targeting" ✓ relevant
Missing: The actual implementation steps!Evaluation Test:
Evaluate % of queries that retrieve sufficient information to answer the question completely
Pitfall #6: Hallucination
Did the generation hallucinate?
Retrieved Context: "Our API rate limit is 1,000 requests per minute"
Generated Answer: "The API supports up to 500 requests per minute
with burst capacity up to 2,000 for enterprise users"
Problem: Where did "500" and "enterprise burst capacity" come from?Evaluation Test:
Force in-text citations in responses and validate each citation exists and is relevant

Pitfall #7: Dynamic Data
When your RAG results change, is it because of a change in the data or the model?
Search result on 2025-01-07: "What is the API rate limit?" => 1,000 requests per minute
Search result on 2025-06-01: "What is the API rate limit?" => 2,500 requests per minuteData is generally not static. This creates a challenge for robust evaluation. You may start getting very different results.
Evaluation Test:
Version and ideally track history of your data

In Summary…
evaluate everything, all the time, independently if possible
AND LOOK AT YOUR DATA.

Questions?
Thank you!
Sign up for my newsletter!
Empowering you to build AI products users love.
Without the late night debugging.
